
Data Visualization
Exploring how data becomes a medium for understanding complex systems.
Overview
A collection of policy-oriented and computational visualization projects exploring how data can function as both a method of inquiry and a medium for communication. Spanning analytical workflows and generative visual systems to reveal social, behavioral, and spatial patterns.
Mapping California’s Solar Divide
This project investigates whether public subsidies targeted toward low-income households actually resulted in increased solar adoption. Instead of relying on statewide statistics, the analysis examines patterns at the ZIP code level, allowing neighborhood-level disparities to surface.
The project reveals where policy incentives succeeded, where they failed, and where unexpected patterns emerged.

Parametric Spatial Visualization
This project explores how everyday consumption data can be translated into spatial form. Using Grasshopper, I built a parametric system that converts behavioral datasets into dynamic landscapes, revealing patterns in how individuals and communities consume resources.
How I Work: Data to Visual System

Project One
California’s Solar Subsidies
Does increased subsidy funding consistently lead to higher solar adoption in low-income ZIP codes?
Research Question
The project began with a simple policy assumption:
If California invests more funding into solar subsidies for low-income communities, solar adoption in those neighborhoods should increase.
However, statewide averages often mask local variation. To better understand the effectiveness of these programs, I focused on neighborhood-level patterns.
Raw Data Collection
Using two independent datasets: solar installation records and public subsidy program data, both aggregated at the ZIP code level to approximate neighborhood-scale policy impacts.

Cleaning & Consolidating
Because the datasets originated from different sources, I used Python (Pandas and NumPy) to clean and consolidate the data. This process ensured that the data could be reliably compared across multiple years and geographic areas.

Exploratory Data Analysis
I examined the relationship between solar subsidies and adoption across ZIP codes. The results suggested that financial incentives alone may not fully explain solar adoption patterns.

Outliers and Patterns
To better understand where the system behaved differently, I identified clusters and outlier communities where adoption patterns diverged from expectations.

Visualization
The final step translated these analytical insights into interactive visualizations. I used D3.js to create a visualization of the data. On the right is the first iteration of the visualization.

Final Data Visualization
Explore the map by county and metric, or follow the analysis where outliers tell the real story.
Project Two
Parametric Spatial Visualization
Can data variation directly drive formal variation, and if so, what spatial systems emerge?
Research Question
The project begins with a conceptual question:
What if the invisible patterns of everyday consumption could be visualized as landscapes?
Modern societies generate enormous amounts of behavioral data—from energy use to digital activity. However, these patterns are often difficult to perceive when represented through conventional statistical charts.
We explored an alternative approach: translating data directly into spatial systems, where variations in data produce variations in form.
Computational Visualization Process
Data Selection
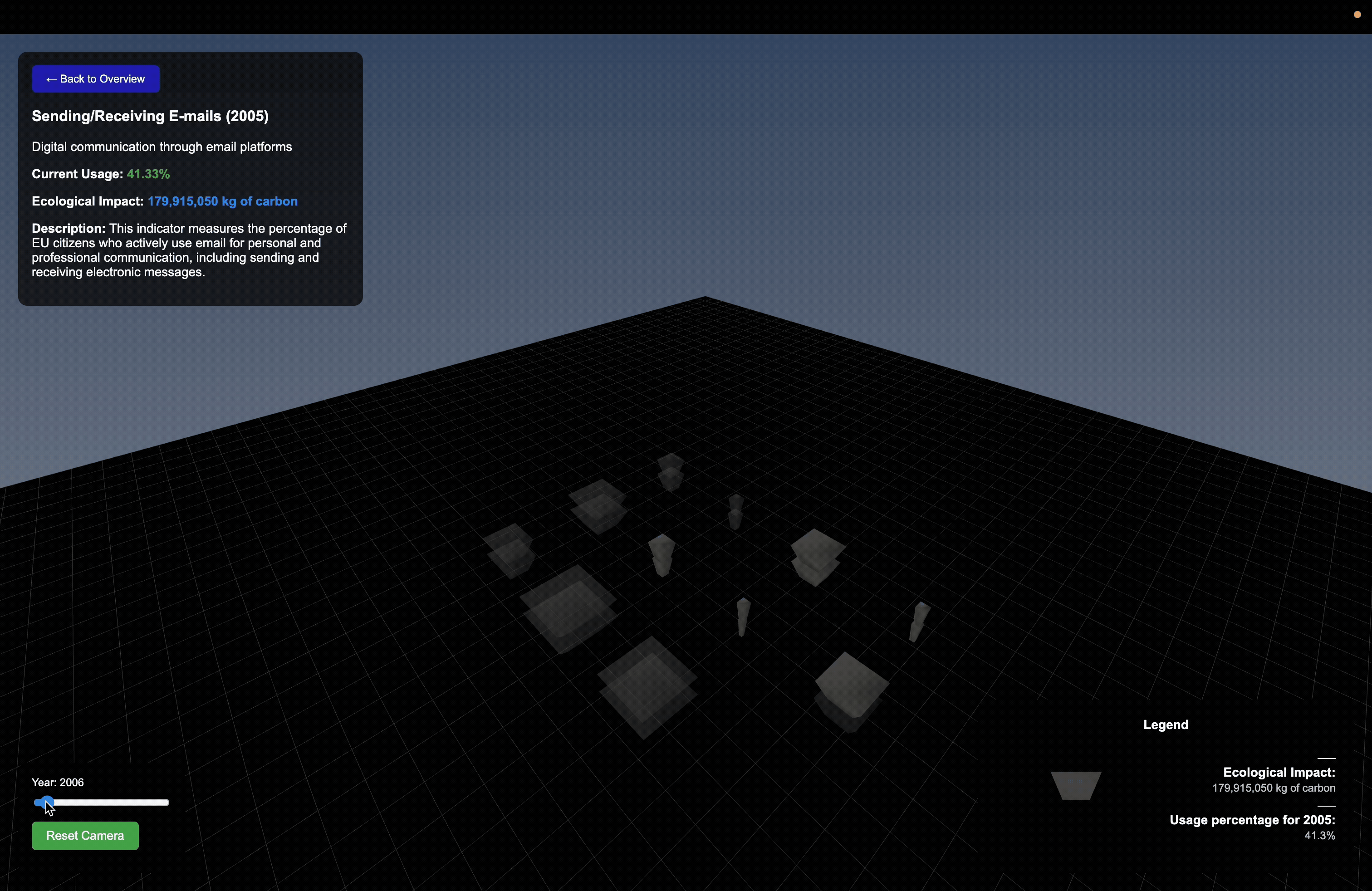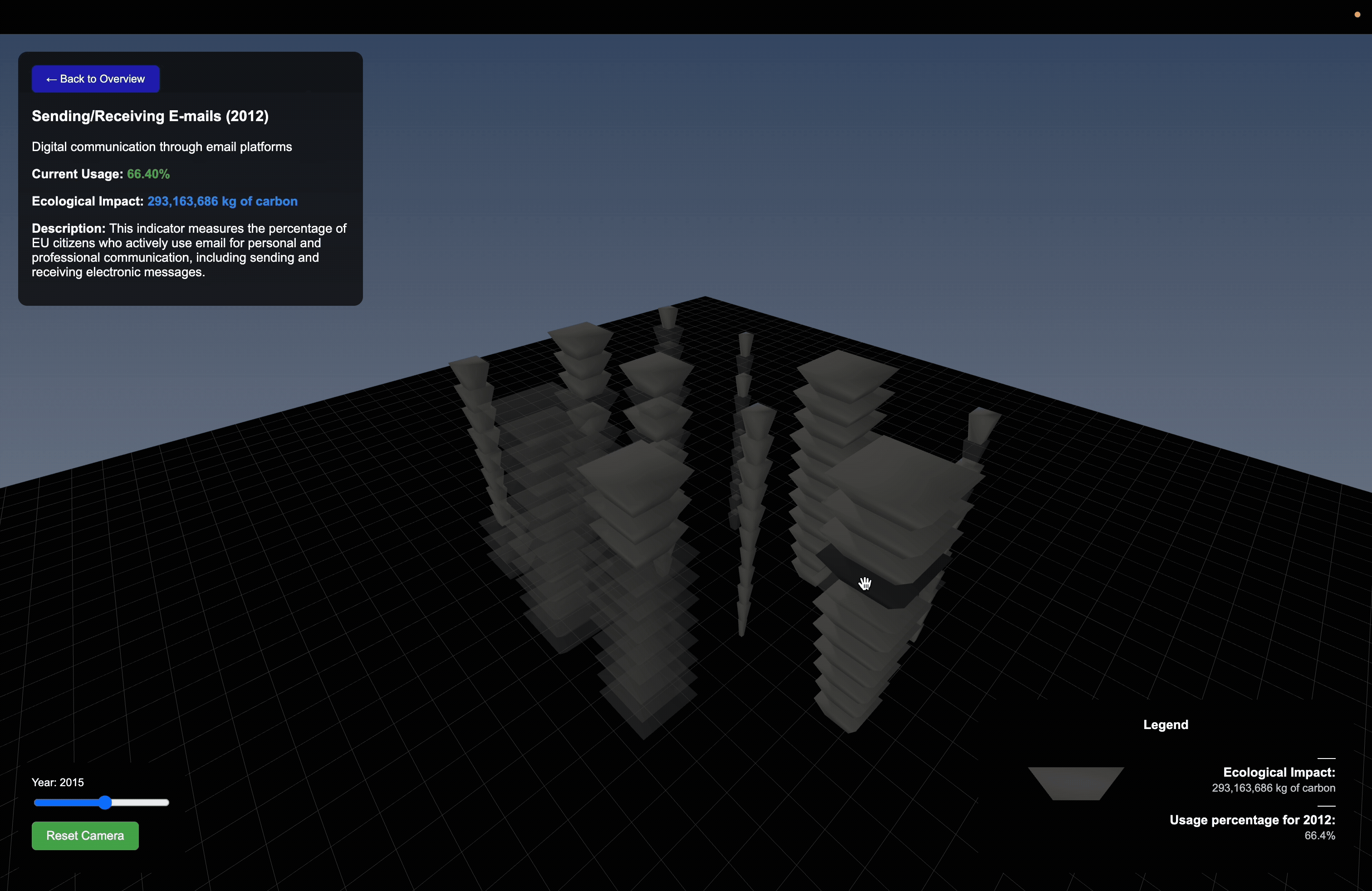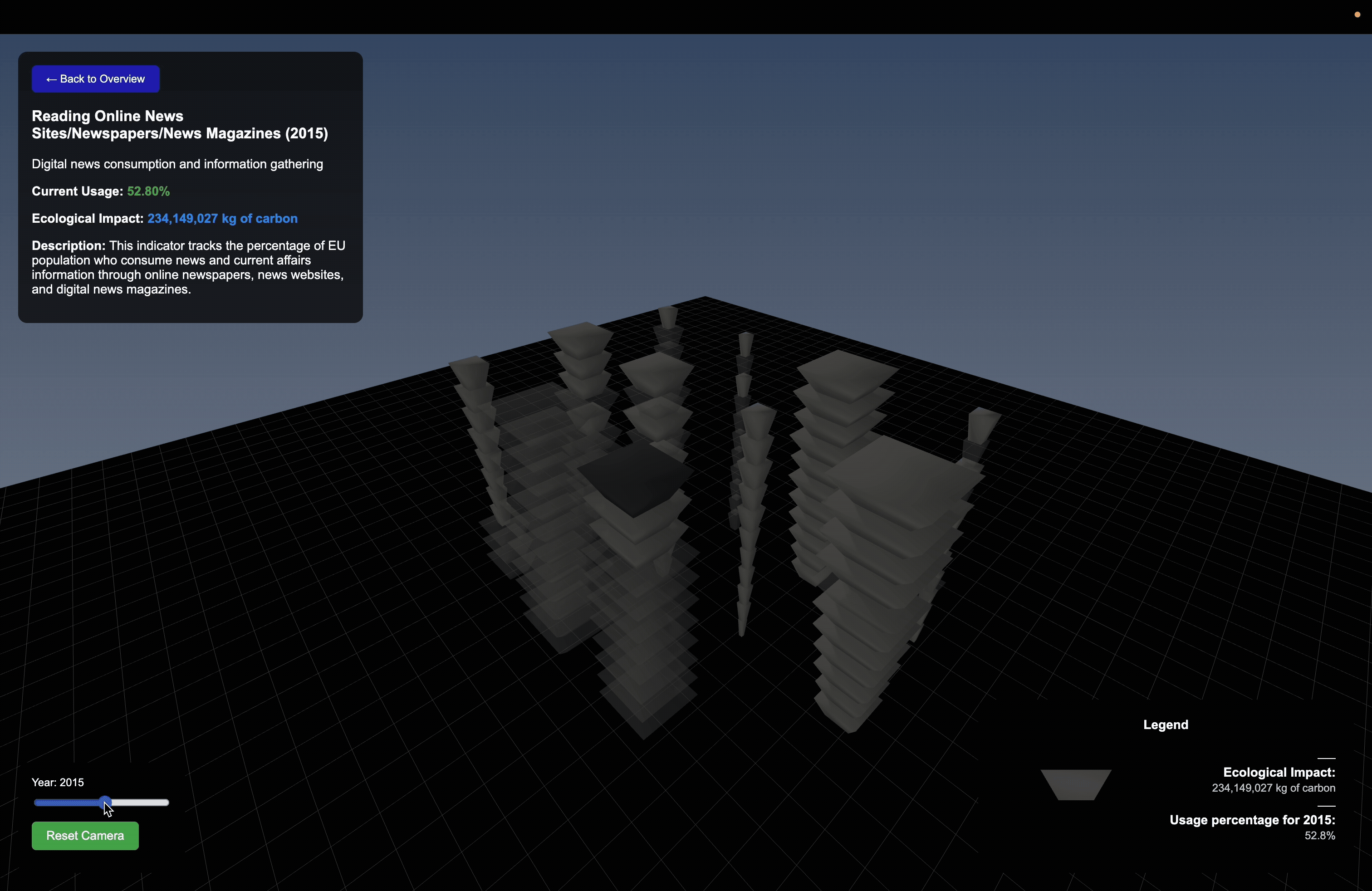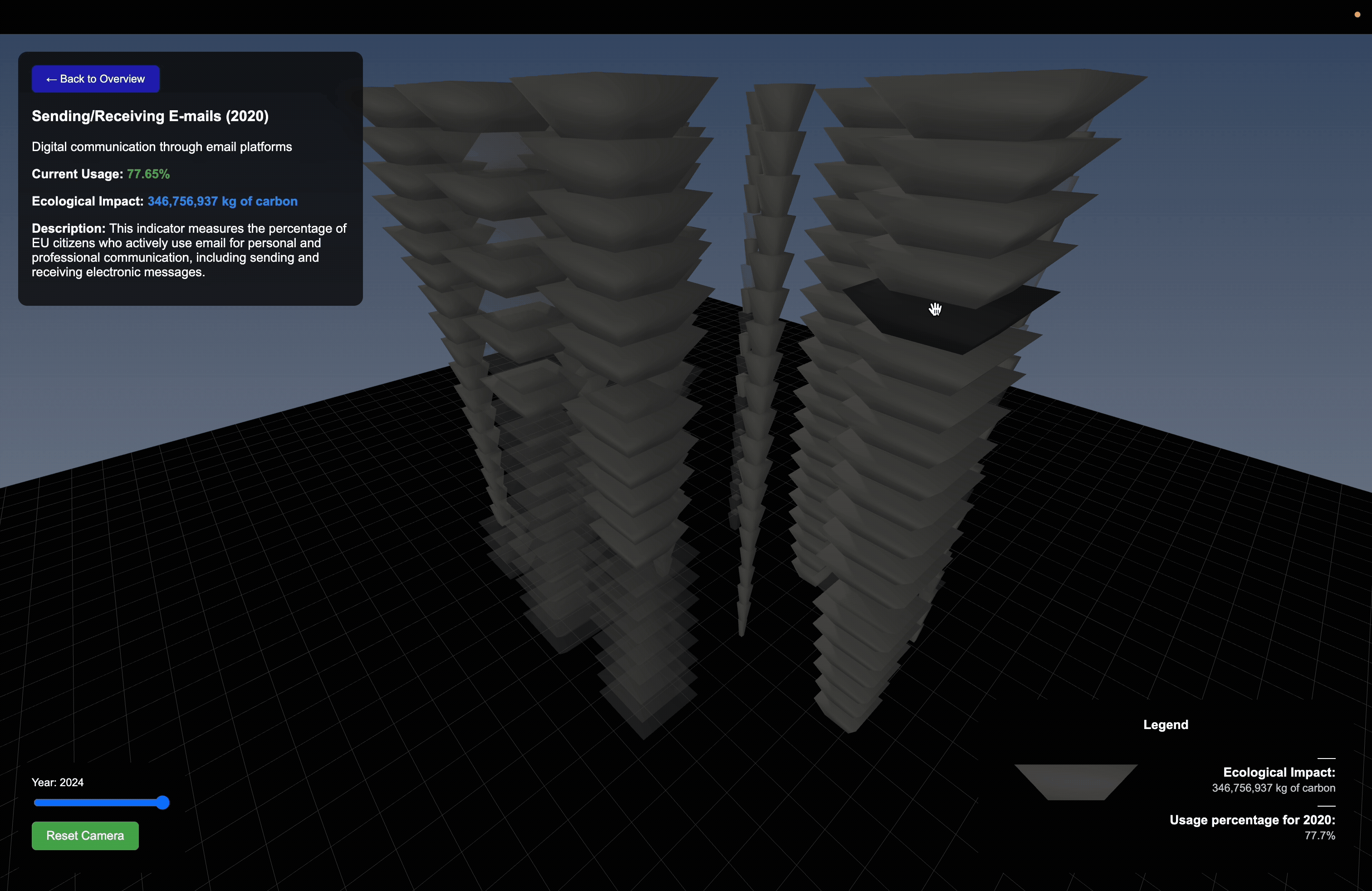
The project draws on EU Online Activity Usage datasets as it captures thecollective behavior and variation across groups rather than any single metric. This provides us the layered input needed to drive a spatially responsive parametric system.

Data Structuring
Each dataset was cleaned, normalized, and mapped to consistent numerical scales so that raw values could directly drive geometric behavior.

Ethnographic Research & Literature Reviews
Grounding the project conceptually, we reviewed cognitive load studies and how information overload shapes behavior and experience.

Design Ideation
We explored how geometry, density, scale, and distribution could be expressed as form. This stage defined the rules and logic later implemented computationally.
Sentiment Analysis
This conceptual layer informed how data was translated into form, treating intensity and difference as design parameters.

Parametric and Computational Generation
Using Rhino and Grasshopper, I developed a parametric system where data directly controls geometric output.
View iterative process
Visual Interpretation
The parametric models make the visualization a responsive system rather than a static representation.

Final Data Visualization

Project Impact

Reveal
surface hidden patterns in complex datasets, making relationships and disparities visible at a more granular level.
Data Exploration
through interactive and computational systems that allow users to compare, filter, and investigate data.
Translate
abstract data into visual and spatial forms, expanding how information can be perceived and understood.
What I learned
Clarity over cleverness
Effective visualization is not about complexity, but about making patterns understandable.
Context shapes interpretation
The same dataset can tell different stories depending on framing, scale, and comparison.
Data can be distorted
This awareness informs how I approach both analytical visualizations and computational systems, ensuring that form does not distort meaning.
Data as systems
Visualization that expands beyond charts into spatial and generative expressions of information.